The GUI carefully avoids updating itself for every block
It takes advantage of multicore systems: it uses one process for the GUI, and another for the data transfer.
This is done using Python's excellent multiprocessing
module, rather than threads.
It shows more statistics than is usual for these tools.
It allows display in SI or IEC units or a mix of the two,
and you can change the units mid-transfer.
Here's a pair of pictures of it in action, both run on an Ubuntu 9.10
system with the following specs:
Dual Core Athlon II X2 245, 2913 MHz
nbench:
memory: 22.359
integer: 20.417
float: 33.831
81967.2 pystones/second
Reading from /dev/zero and writing to /dev/null.
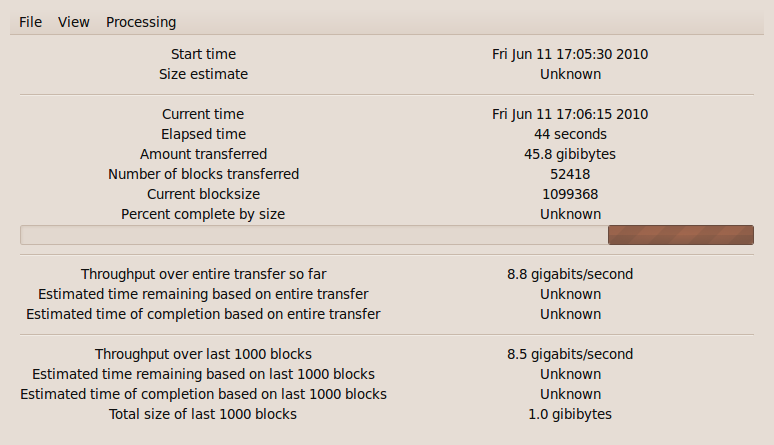
Here the CPU is the limiting factor.
Because you can't get a length estimate out of /dev/zero, the
progress bar is pulsing back and forth, not progressing. Also
for this reason the ETA's are "Unknown".
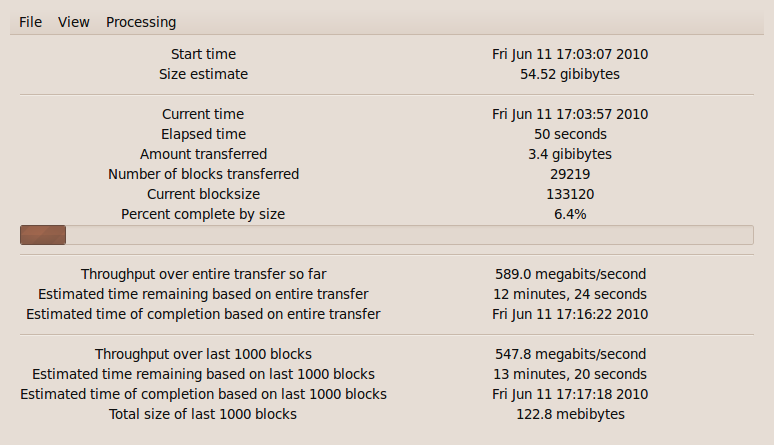
Reading from a tar process that's reading from disk, and
writing to /dev/null.
Here the disk or perhaps the interprocess communication
is the limiting factor.
This is really invoked via gprog-du-tar, so we have
a length estimate, hence the progress bar is growing from the
left. Also, we have ETA data.
Here are some gprog wrappers that compute estimates and invoke gprog for you:
gprog-backshift-extract
Usage: ./gprog-backshift-extract
--save-directory Specify the backshift repo. Required
--starting-directory Specify the backshift starting directory. Optional
--backup-id Specify the backshift backup ID. Required
--tar-format fmt gnu or ustar. pax can be expected to fail
--help This stuff
This script will compute how much disk space is used by a given backshift backup, and use that to give an ETA for
an extraction.
gprog-buf
Usage: ./gprog-buf arg1togprog arg2togprog .. argntogprog
Just write stdin to a temporary file, and then start gprog on it. Output goes to stdout.
This is really only useful when writing from gprog to a slow device or socket.
gprog-clone-partition
Usage: ./gprog-clone-partition
--source-partition /dev/sdb1
--allow-mounted-source
--destination-partition /dev/sdd1
--dry-run
--help
Clone a partition to another partition on the same computer.
Consider using fsck on your source partition before running this script.
On XFS, that might look like: xfs_repair /dev/sdb1
Also, you may or may not want to generate a new UUID for your destination
filesystem after running this script. On XFS, that might look like:
xfs_admin -U generate /dev/sdd1
gprog-df-tar
Usage: ./gprog-df-tar
--mount-point A single directory that is a mount point
--help This stuff
Tar up a local filesystem and pipe it through gprog, using df to get an estimate of how much data will need to be copied.
gprog-du-tar
Usage: ./gprog-du-tar
--directories A list of directories to du and tar - must be the last option
--help This stuff
Tar up a directory hierarchy and pipe it through gprog, using du to get an estimate of how much data will need
to be copied.
gprog-ssh-df-tar
Usage: ./gprog-ssh-df-tar
--host The host to log into to transfer the filesystem from. Can also be of the form username@host
--mount-point A single directory that is a mount point
--help This stuff
Tar up a remote filesystem and pipe it through gprog, using remote df to get an estimate of how much data will need to
be copied.
Please note that this script will ssh-copy-id
gprog-ssh-du-tar
Usage: ./gprog-ssh-du-tar
--host The hostname to ssh to
--directory A directory to ssh to and du+tar. Note that ~ does not work in this
--compressor Specify what program to compress with, if any. Valid options include cat, gzip, bunzip2 and xz
--help This stuff
Tar up a directory hierarchy and pipe it through gprog, using du to get an estimate of how much data will need
to be copied.
Please note that this script will ssh-copy-id
Rarely, the GUI won't come up until the transfer is complete. I believe this to be an issue on machines with
almost no free physical memory - EG, it happened on a system with a huge ramfs (ramdisk).
gprog is not suitable for (direct) use with traditional tape drives, because most tape drives want tape blocks to
be of a consistent size. gprog gets a lot of its performance by sacrificing blocksize consistency - this is fine
for disk and network, but typically not for tape.
If you need (GUI) progress with a tape drive, consider putting something like
dd at the end of your pipeline.
The popup signaling a complete transfer is modal. It's no longer modal.